From Noisy Retrieval to Precision: Building a Production RAG Pipeline for Indian Tax Law
Building a Retrieval-Augmented Generation (RAG) system that performs well in real-world scenarios is rarely a straight path. My initial implementation started with a standard pipeline, but the evaluation results were not satisfactory. This blog walks through the iterative improvements I made—from data preparation to advanced retrieval and chunking strategies—that eventually led to a significantly better-performing system.
Background
Indian tax law — GST, Income Tax, circulars, notifications — is dense, cross-referential, and unforgiving of ambiguity. A chatbot that retrieves the wrong section confidently is worse than one that admits it doesn't know. Getting retrieval right is not optional; it's the whole game.
This post documents the full journey of building a production RAG pipeline for a tax Q&A system: data collection, chunking, vector ingestion, hybrid search, reranking, and finally the technique that made the biggest difference — contextual chunking.
Stage 1: Data Collection and Corpus Preparation
The first step was sourcing and cleaning the raw corpus: GST acts, Income Tax Act sections, CBDT/CBIC circulars, notifications, and FAQs. Each document was parsed and enriched with structured metadata before storage:
source— act name, circular number, or notification referencesection/chapter— structural position within the documenteffective_date— relevant for time-bound provisionsdocument_type— act | circular | notification | FAQ
Metadata isn't decoration — it becomes a filter layer during retrieval, letting you scope searches to a specific document type or date range.
Stage 2: Chunking Strategy (v1 — Naive Overlap)
Standard recursive character splitting with overlap. Chunks of ~400–500 tokens with a 50-token overlap, metadata injected into each chunk's payload.
The intuition behind overlap is sound: if a concept spans a chunk boundary, the overlap ensures neither chunk loses it entirely. In practice, for dense legal text, this assumption breaks. A 50-token overlap cannot carry the subject of a section header that appeared 300 tokens ago.
Ingested into a Qdrant vector store using BAAI/bge-m3 embeddings (dense-only, 1024 dimensions).
Stage 3: Baseline Evaluation
A hand-labelled evaluation set of 100 question–answer pairs was prepared, covering a representative spread of GST and Income Tax queries — section lookups, rate queries, exemption conditions, filing deadlines, and cross-act references.
Baseline retrieval metrics (naive chunks + semantic search only):
| Metric | Score |
|---|---|
| Faithfulness | 0.9360 |
| Context Precision | 0.2305 |
| Context Recall | 0.149 |
| Answer Correctness | 0.258 |
The numbers confirmed what manual inspection already showed: chunks were being retrieved that were semantically adjacent to the query but not actually answering it. The model was picking up on tax-domain vocabulary without landing on the right provision.
Stage 4: Hybrid Search — Semantic + BM25
The first major improvement came from combining dense vector search with BM25 lexical matching.
Why BM25 matters for legal text
Embedding models are excellent at capturing semantic meaning — "what is the GST rate on this type of service" maps well to the right embedding neighbourhood. But legal text is full of terms that need exact matching: section numbers (Section 80C), notification references (Circular No. 183/15/2022), HSN codes, specific defined terms. An embedding model might correctly associate 80C with deductions but miss the specific sub-section being asked about. BM25 catches these exact-match signals.
BM25 builds on TF-IDF (Term Frequency-Inverse Document Frequency) — measuring how significant a term is relative to the full corpus — and refines it with document-length normalisation and term saturation to prevent common words from dominating results.
Reciprocal Rank Fusion (RRF)
Results from semantic search and BM25 are merged using Reciprocal Rank Fusion. RRF assigns each chunk a score based on its rank in each list (not its raw similarity score), then sums these across both lists. This avoids the score-scale mismatch between cosine similarity and BM25 scores, producing a stable combined ranking.
Metrics after hybrid search + RRF:
| Metric | Baseline | Hybrid Search |
|---|---|---|
| Faithfulness | 0.9360 | 0.9234 |
| Context Precision | 0.2305 | 0.3510 |
| Context Recall | 0.149 | 0.213 |
| Answer Correctness | 0.258 | 0.3111 |
Stage 5: Reranking
After fusion, the top-K candidates are re-scored by a cross-encoder reranker. Unlike bi-encoder embeddings (which encode query and document independently), a cross-encoder takes the (query, chunk) pair jointly and produces a relevance score with full attention across both.
This is significantly more compute-intensive — you cannot precompute cross-encoder scores at index time — but since it only runs on the top-K candidates (typically 20–50), the latency overhead is manageable.
For a tax domain, reranking provides a meaningful signal: a chunk about GST input tax credit and a chunk about income tax deductions may embed similarly against a generic "tax credit" query, but a cross-encoder can distinguish the domain mismatch.
Metrics after hybrid search + reranking:
| Metric | Baseline | Hybrid | Hybrid + Rerank |
|---|---|---|---|
| Faithfulness | 0.8560 | 0.9234 | 0.9364 |
| Context Precision | 0.2305 | 0.3510 | 0.4108 |
| Context Recall | 0.149 | 0.213 | 0.4494 |
| Answer Correctness | 0.258 | 0.3111 | 0.4566 |
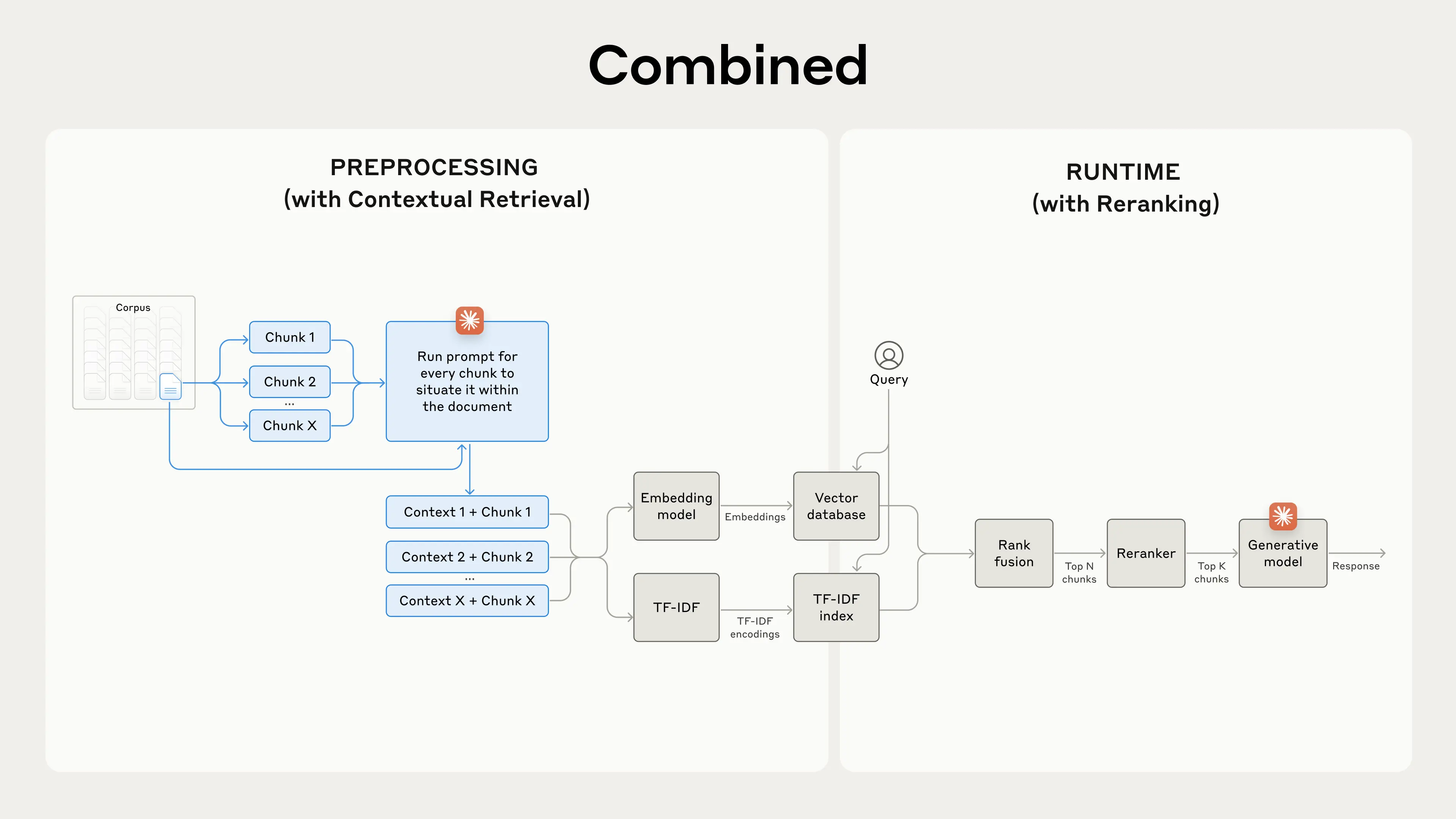
Stage 6: Contextual Chunking — The Game Changer
Even with hybrid search and reranking, a root cause remained unaddressed: chunks were stripped of the context they needed to be interpretable.
Consider a chunk extracted from the GST Act:
"The registered person shall not be allowed to take input tax credit in respect of any supply of goods or services or both after the due date..."
This is a perfectly valid sentence. But without knowing which section it comes from, which financial year's amendment applies, or what "registered person" refers to in context — it's ambiguous. A retrieval system can fetch it, but an LLM generating an answer from it may fill in the wrong context.
The Contextual Chunking Approach
Contextual chunking, introduced by Anthropic, prepends a short LLM-generated context summary to each chunk before embedding it and building the BM25 index. The context is generated by passing the full source document alongside the target chunk to the model with this prompt structure:
<document>
{{Context}}
</document>
<chunk>
{{CHUNK_CONTENT}}
</chunk>
Give a short, succinct context (50–100 tokens) that situates this chunk within
the overall document to improve search retrieval. Respond only with the context.
The output for the chunk above might become:
"This chunk is from Section 16(4) of the CGST Act 2017, which sets the time limit for claiming input tax credit by a registered taxpayer. The company's revenue grew by 3% over the previous quarter."
This 50–100 token prefix — added to both the embedding and the BM25 index — dramatically increases the chunk's specificity. Retrieval now benefits from the document-level signal without requiring the entire document to be embedded.
Note on cost: Generating context for every chunk at indexing time does incur LLM API costs. For large corpora, prompt caching (available on the Claude API) can reduce this significantly — up to 90% cost reduction on repeated document prefixes.
Why Other Approaches Underperform
Generic document summaries appended to chunks provide marginal gains — a summary of the entire GST Act tells you very little about which specific provision a chunk belongs to. Hypothetical Document Embedding (HyDE) and summary-based indexing have also been benchmarked and show lower performance than chunk-specific contextualisation for retrieval tasks.
Metrics after contextual chunking:
| Metric | Baseline | Hybrid + Rerank | Contextual + Hybrid + Rerank |
|---|---|---|---|
| Faithfulness | 0.8560 | 0.9234 | 0.9364 |
| Context Precision | 0.2305 | 0.3510 | 0.4108 |
| Context Recall | 0.149 | 0.213 | 0.4494 |
| Answer Correctness | 0.258 | 0.3111 | 0.4566 |
Anthropic's benchmarks on their datasets show contextual retrieval reducing failed retrievals by 49% over standard embedding-only RAG, and by 67% when combined with reranking. Results in domain-specific corpora like legal/tax text tend to be on the higher end of this range due to how heavily context-dependent the language is.
Full Pipeline Architecture
Raw Documents (GST Act, IT Act, Circulars, Notifications)
│
▼
Metadata Extraction
(source, section, effective_date, doc_type)
│
▼
Recursive Text Chunking (~400-500 tokens)
│
▼
Contextual Prefix Generation (LLM, per chunk)
│
┌─────────────────┐
▼ ▼
Dense Embedding BM25 Index
(bge-m3, 1024d) (contextual chunks)
→ Qdrant │
│ │
└──────┬───────┘
▼
Reciprocal Rank Fusion
│
▼
Cross-Encoder Reranker
│
▼
Top-K Chunks → LLM → Answer
Key Takeaways
Overlap alone doesn't solve context loss. For technical/legal text where document structure carries meaning, naive overlap is insufficient. Context needs to be explicitly injected.
BM25 is not obsolete. Lexical matching remains essential for identifier-heavy domains — section numbers, notification codes, HSN codes. Pure semantic search misses these.
Reranking is the cheapest meaningful improvement. Cross-encoder reranking on top-K candidates adds latency (100–300ms typically) but no indexing cost, and the quality gain is significant.
Contextual chunking compounds with everything else. It improves both the embedding quality and the BM25 index simultaneously, so every downstream step benefits.
Evaluation set quality is everything. 100 hand-labelled Q&A pairs covering the actual distribution of user queries is worth more than automated generation at 10x the size. Garbage evals produce misleading metrics.